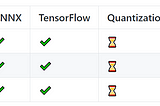
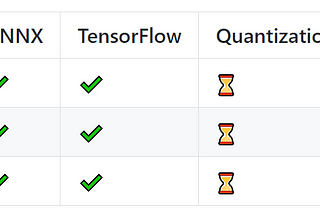
Alexander VeysovA Pre-trained Model to Restore Punctuation and Capital Letters in 4 LanguagesOriginally published at https://habr.com on October 6, 2021.4 min read·Oct 6, 2021----
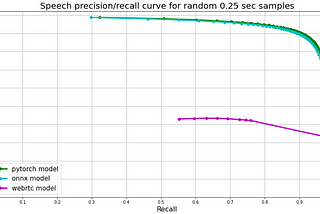
Alexander VeysovinTowards Data ScienceModern Portable Voice Activity Detector ReleasedCurrently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector (…3 min read·Jan 14, 2021----
Alexander VeysovinTowards Data SciencePlaying with Nvidia’s New Ampere GPUs and Trying MIGIs upgrading to Ampere worth it?12 min read·Dec 5, 2020----
Alexander VeysovModern Google-level STT Models ReleasedOur models are on par with premium Google models and also really simple to use2 min read·Sep 18, 2020----
Alexander VeysovinTowards Data ScienceTowards an ImageNet Moment for Speech-to-TextThis piece will describe our pursuit of an ImageNet moment for STT12 min read·Mar 28, 2020----
Alexander VeysovinTowards Data ScienceOpen STT 1.0 releaseFinally we made it!3 min read·Nov 4, 2019----
Alexander VeysovNavigating the Speech to Text Dark ForestMake your ASR network 4x faster, 5x smaller and 10x cooler18 min read·Aug 12, 2019----
Alexander VeysovinTowards Data ScienceRussian Open Speech To Text (STT/ASR) Dataset4000 hours of STT data in Russian8 min read·May 2, 2019----
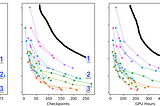
Alexander VeysovinTowards Data ScienceComplexity / generalization /computational cost in NLP modeling of morphologically rich languagesTransformer is not yet really usable in practice for languages with rich morphology, but we take the first step in this direction13 min read·Mar 7, 2019--1--1
Alexander VeysovinTowards Data ScienceWinning a CFT 2018 spelling correction competitionOr building a task-agnostic seq2seq pipeline on a challenging domain12 min read·Nov 22, 2018----